
1변량 데이터
하나의 변량(종류)만 있는 데이터를 1변량 데이터라고 합니다.
기본적인 통계량
기본적인 통계용어들을 익히도록 하겠습니다
- 총합(sum)
- 평균값(average)
- 표본분산 - 표본평균을 사용하여 분산을 계산한 값
- 수식 : \[\sigma^2 =\frac{1}{N} \sum_{i=1}^N (x_i - \mu)^2\]
- 불편분산 - 표본분산의 과소추정 경향을 보정하기 위한 개념, 불편분산
- 수식 : \[\sigma^2 =\frac{1}{N-1} \sum_{i=1}^N (x_i - \mu)^2 \]
- 표준편차
- 표준화 - 데이터의 평균을 0으로, 표준편차(분산)을 1로 하는 변환을 표준화라고합니다. 가량 키의 1cm와 몸무게 1kg간격의 차이는 동일한 것을 의미하지않기때문입니다. 이와 같은 표준화를 하는 이유는 큰 변수와 작은 변수둘이 섞여있다면 그 분석이 유의하지않기 때문입니다.
- 최대, 최소값
- 최대값 - scipy.amax / 최소값 - scipy.amin 활용하여 쉽게 구할 수 있음
- 중앙값(scipy.mdeian) ≠ 평균값
- 중앙값과 평균값은 같을 수는 있지만, 항상 같지는 않음
- 데이터의 이상치(매우 큰 값 또는 매우 작은 값이 발생)가 있는 경우, 중앙값은 그 데이터의 영향을 받지않습니다. 하지만, 평균값은 영향을 받습니다.
- 사분위(Quantile)
- scipy의 status를 활용하여 사분위값을 구할 수 있음
- 작은 값부터 쭉 펼쳐놨을때 해당하는 25% 또는 75%에 해당하는 값을 표출함
import numpy as np
import scipy as sp
from scipy import stats
data = np.array([1,2,3,4,5,6,7,8,9])
stats.scoreatpercentile(data , 25) # 결과값 3
stats.scoreatpercentile(data , 75) # 결과값 3
다변량 데이터
여러개의 변수를 조합한 데이터. 즉, 2개 이상의 변수를 가진 데이터 의미함
- 그룹별 통계량 계산하기 - pandas의 groupby 함수
import scipy as sp
import pandas as pd
data = pd.read_csv("./data.csv")
group = data.groupby("species")
print(group.mean())
group.describe()
2개의 연속형 변수의 관계성 파악 - 공분산(Covariance)
\[ Cov(x,y) = \frac{1}{N} \sum_{i=1}^N (x_i - \mu_x)(y_i-\mu_y)\]
해석 : 공분산의 결과가 0보다 큰 값을 때, 변수 x가 평균값보다 큰 값일 때, 다른 변수 y도 평균보다 큰 값을 가진다고 해석할 수 있음
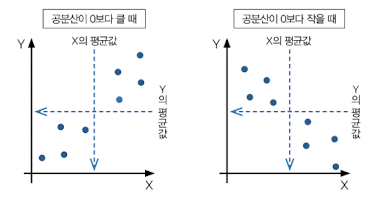
- 공분산이 0보다 큰 경우, 변수 한쪽이 큰 값을 갖게되면 다른 한쪽도 커짐
- 공분산이 0보다 작을 때, 변수 한 쪽이 큰 값을 갖게되면 다른 한쪽은 작아짐
- 공분산이 0일때, 변수 사이에 관계성은 없음
상관계수
상관분석은 두가지 또는 그 이상의 변량에 대해 상호관계성을 분석하는 방법으로 피어슨, 스피어만, 켄달, 점 양분, 파이 계수가 있습니다.
- 피어슨 상관계수
- 연속형 변수와 연속형 변수간의 선형관계 파악시 활용
- 다만, 두 변수 모두 정규성을 따른다는 가정이 필요
\[ \rho_{xy} = \frac{Cov(x,y)}{ \sqrt{ \sigma_x^2 \sigma_y^2}} \]
- 스피어만 순위 상관계수
- 두 변수가 정규성을 따르지 않는 경우, 피어슨 상관계수를 활용할 수 없기에 순위 상관계수 방법 활용
- 순위를 이용하기 땨문에 비모수적 방법
- 켄달
- 점 양분 상관계수
- 파이계수
다변량 데이터 시각화
시각화 방안
- 상자그림(boxplot)
- 바이올린플롯
- 막대그래프
- 산포도(sns.jointplot)
- 페어플롯(sns.pariplot)
Reference
- (도서) 파이썬으로 배우는 통계학 교과서
- 상관분석의 종류 - http://www.incodom.kr/%EC%83%81%EA%B4%80%EB%B6%84%EC%84%9D_%EC%A2%85%EB%A5%98
비전공자의 데이터 사이언티스트 도전기
728x90
반응형
'Python > 2️⃣ 데이터 처리' 카테고리의 다른 글
| [머신러닝] 결정트리 실습 - Pima Indians Diabetes Database (0) | 2023.03.03 |
|---|---|
| 간단한 통계 개념 정리 (0) | 2023.02.14 |
| 불편분산은 왜 n-1로 나누지? (0) | 2023.02.12 |
| [머신러닝] 타이타닉 생존자 예측하기 (0) | 2023.02.06 |
| [머신러닝] 사이킷런으로 시작하는 머신러닝 (0) | 2023.02.06 |