
주제: 사이킷런으로 시작하는 머신러닝
작성: 2023-02-04버젼: pandas 1.4.4 / sklearn 1.1.1
활용데이터: 붓꽃 데이터(from sklearn.datasets import load_iris)
안녕하세요, 루카스입니다.
오늘은 파이썬 머신러닝으로 가장 많이 활용되는 라이브러리, 사이킷런(scikit-learn)을 소개합니다.
우선, 머신러닝이란?
학습을 위해서 다양한 피처와 분류결정값인 레이블 데이터를 모델로 학습한 뒤, 별도의 테스트를 통해서 미지의 레이블을 예측 및 분류하는 것 방법입니다. 다시말해, 지도학습은 명확한 정답이 주어진 데이터를 먼저 학습한 뒤 미지의 정답을 예측하는 방식입니다.
- 머신러닝은 크게 지도학습(supervised Learning)과 비지도학습으로 나눠짐
- 머신러닝 프로세스는 다음과 같음

1. 붓꽃 품종 예측
1.1. 전체코드
skelarn의 기본적으로 머신러닝을 연습할 수 있도록 데이터셋을 제공합니다. 해당 제공되는 붓꽃데이터를 통해서 머신러닝 중 의사결정나무를 이용하여 예측을 진행해보도록 하겠습니다.
import sklearn
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# 데이터셋 준비 - 붓꽃 데이터
iris = load_iris()
iris_data = iris.data
iris_label = iris.target
# 데이터 전처리 - DataFrame으로 변환
df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
df['label'] = iris.target
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label,
test_size=0.2, random_state=11)
# 모델 생성 - DecisionTreeClassifier객체 생성
dt_clf = DecisionTreeClassifier(random_state=11)
# 모델 수행 - 학습
dt_clf.fit(X_train, y_train)
# 예측
pred = dt_clf.predict(X_test)
# 평가
from sklearn.metrics import accuracy_score
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test,pred))) #예측정확도 : 0.9333부연 설명
- 데이터셋 : from sklearn.datasets import load_iris
- train_test_split() 속성
- test_size : default =0.25
- shuffle : default = true
- 반환값은 튜플형태로 반환함
다만, 해당 코드만으로는 의사결정나무이 어떤 방식으로 값들을 분류하는지 확인이 어렵습니다.
- export_graphviz
- 학습된 classifer 입력을 하면, dot파일을 생성
- export_graphviz는 class_names와 feature_names 반듯이 필요
import sklearn
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# 데이터셋 준비 - 붓꽃 데이터
iris = load_iris()
iris_data = iris.data
iris_label = iris.target
# 데이터 전처리 - DataFrame으로 변환
df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
df['label'] = iris.target
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label,
test_size=0.2, random_state=11)
# 모델 생성 - DecisionTreeClassifier객체 생성
dt_clf = DecisionTreeClassifier(random_state=11)
# 모델 수행 - 학습
dt_clf.fit(X_train, y_train)
# 의사결정나무 시각화
from sklearn.tree import export_graphviz
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris.target_names,
feature_names = iris.feature_names, impurity=True, filled=True)
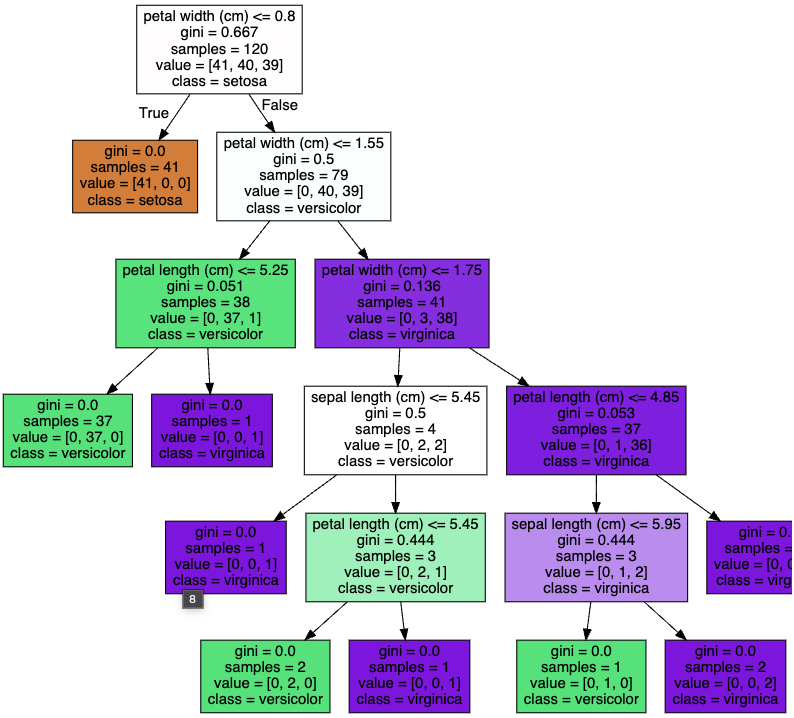
2. 교차검증
ML알고리즘에서 최적으로 동작할 수 있도록 데이터를 선별해서 학습한다면 어떤 일이 발생할까요?
열심히 알고리즘을 개발하여 높은 정확도를 가진 모델을 만들었다고해도 실제 데이터을 넣었 때는 차이가 발생하며, 이에 따라 성능 저하가 발생하게 될 것입니다. 이런 데이터 편중을 막기위해서 여러 세트로 구성된 데이터세트와 검증 데이터 세트에서 학습과 평가를 수행하는 것이며, 이에 따라 하이퍼 파라미터 등의 모델 최적화를 가능케 하죠
- k-fold 교차검증
- Stratified K-fold
- 불균형한 분포도를 가진 데이터 집합을 위한 교차검증방식으로, 특정 레이블 값이 특이하게 많거나 부족하여 값의 분포가 한쪽이 치우는 경우에 사용합니다. 이는 학습 및 테스트 데이터셋에서 제대로 분배하지 못한 경우의 문제도 해결하는 효과가 있음
- 예시) 대출사기데이터가 있다고 가정했을때, 대출사기에 해당하는 레이블의 값
- 예시) 10년간의 날씨데이터에서의 폭우에 해당하는 레이블의 값
- 불균형한 분포도를 가진 데이터 집합을 위한 교차검증방식으로, 특정 레이블 값이 특이하게 많거나 부족하여 값의 분포가 한쪽이 치우는 경우에 사용합니다.
- 불균형한 분포도를 가진 데이터 집합을 위한 교차검증방식으로, 특정 레이블 값이 특이하게 많거나 부족하여 값의 분포가 한쪽이 치우는 경우에 사용합니다. 이는 학습 및 테스트 데이터셋에서 제대로 분배하지 못한 경우의 문제도 해결하는 효과가 있음
- 교차검증 및 하이퍼 파라미터 튜닝을 한번에 할 수 있도록 도움을 주는 GridSearchCV
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
# 데이터 분리
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=121)
dtree = DecisionTreeClassifier()
# parameter 들을 dictionary 형태로 설정
parameters = {'max_depth':[1,2,3], 'min_samples_split':[2,3]}
# param_grid의 하이퍼 파라미터들을 3개의 train, test set fold 로 나누어서 테스트 수행 설정
grid_dtree = GridSearchCV(dtree, param_grid=parameters, cv=3 )
# param_grid의 하이퍼 파라미터들을 순차적으로 학습/평가 .
grid_dtree.fit(X_train, y_train)
# GridSearchCV 결과 추출하여 DataFrame으로 변환
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score', \
'split0_test_score', 'split1_test_score', 'split2_test_score']]
3. 데이터전처리
데이터전처리과정도 알고리즘 만큼 중요합니다. 왜냐하면 알고리즘의 경우, 데이터에 기반하기 때문에 어떤 데이터를 입력하는지에 따라서 그 결과도 크게 달라질 수 있기 때문입니다.
- 데이터인코딩
- 레이블인코딩
- 원핫인코딩(ONE_HOT Encoding)
- 피처스케링과 정규화
- StandardScaler
- MinMaxScaler
이는 데이터 특성에 따라 어떤 방식으로 전처리해야할지 판단하여 사용해야합니다.
Reference
- 미리캔버스 : https://www.miricanvas.com/
- 파이썬 머신러닝 완벽가이드 github : https://github.com/wikibook/ml-definitive-guide
- 의사결정나무 시각화 : https://foxtrotin.tistory.com/443
'Python > 2️⃣ 데이터 처리' 카테고리의 다른 글
| 불편분산은 왜 n-1로 나누지? (0) | 2023.02.12 |
|---|---|
| [머신러닝] 타이타닉 생존자 예측하기 (0) | 2023.02.06 |
| [알고리즘] 각도기 (0) | 2023.01.12 |
| [Kaggle]Binary classification : Tabular data (0) | 2022.08.15 |
| 차원 축소(Dimension Reduction) (0) | 2022.02.06 |