
개발자L
주제 : 머신러닝과 딥러닝의 전반적인 이해
4차 산업에서 중요한 것 바로 데이터(Data)입니다. 최근 데이터에 중요성이 강조되면서 데이터 분석가, 머신러닝 및 인공지능 업종에 대한 수요도 지속적으로 늘어나고 있습니다. 그렇다면 데이터 분석이란 무엇이며, 머신러닝과 딥러닝은 무엇인지 한번 알아보도록 하겠습니다.

1. 데이터분석(Data Analytics)
데이터 분석과 관련해서 검색을 하다 보면, 데이터마이닝이라는 표현을 들어본 적이 있으실 겁니다.사실상 데이터 분석과 데이터마이닝은 유사한 표현입니다. 단지 해당 분야에 따라서 일컫는 방식이 다를 뿐이죠. 통계냐? 머신러닝이냐?
그렇다면 데이터 분석이란 무엇일까요? 데이터 분석이란 데이터의 특징을 확인하는 것이라고 할 수 있습니다. 여기서 데이터란 datum(자료)의 복수형으로서, 데이터 자체를 조금 더 이해하기 쉬운 용어로 바꾸면 Group이라고 할 수 있습니다.
그렇다면, 데이터 분석이란 데이터의 특징을 확인하는 것이라고 했는데... 다시말해, 그룹의 특징을 확인하는 것이라고 할 수 있습니다.그렇다면 여기서 말하는 특징은 무엇일까요? 크게 두 가지의 특징을 자주 얘기하곤 합니다. 바로 평균(중심화 경향치), 분산(떨어져 있는 정도, 산포도)입니다.
정리하면, 그룹에서의 데이터가 어디에 몰려있는지 또한 그 평균을 기점으로 얼마만큼 떨어져 있는 것을 분석함으로써 과거의 특징을 파악하여 미래의 상황, 결과, 특징을 예측 또는 분류하는 것이 우리가 데이터 분석을 하는 이유이자 목적입니다.
2. 데이터의 저장

3. 효율적인 통계
중심 극한의 정리에 의해 우리는 최소 30개 이상의 표본이 있으면, 그 데이터를 가지고 모집단을 추정할 수 있다고 알려져 있다.하지만, 실제로는 최소 100-200개의 데이터를 이용해서 통계 및 분석을 실시한다. 다시 말해 현재까지 통계학은 효율적인 통계이다.쉽게말해 적은 데이터들을 통해서 효율적인 통계를 진행하다 보니, 통계적인 방법을 통해서 추정한 뒤, 검정하는 단계가 필수적이다.

하지만, 현대에는 데이터도 많아졌을 뿐 아니라, (여기서 말하는 데이터는 아날로그 데이터가 아닌 디지털 데이터를 일컫음)컴퓨터의 계산속도 등 컴퓨터의 발전으로 다음과 같은 방법이 필요 없이 지면서 새로운 방법이 대두된 것입니다.이것이 바로 머신러닝과 딥러닝 방식입니다. 즉, 머신러닝과 딥러닝은 검정하는 단계가 필요가 없습니다.
4. 데이터의 형태
데이터의 형태는 크게 정형과 비정형 데이터로 나눌 수 있습니다.(사실 정형/반 정형/비전형 데이터로 3개로 나뉨)
정형 데이터(structured data)라는 것은 데이터의 형태가 정해져 있는 것을 뜻합니다. 비정형 데이터(unstructured data)은 데이터의 형태가 정해져 있지 않을 것을 말합니다
사실 머신러닝과 딥러닝은 전혀 다른 것처럼 느껴지지만, 머신러닝 중 비정형 데이터 분석에 특화되기 위해 하나를 떼어다가 만들어진 것이 딥러닝입니다.
지금까지의 내용을 정리해본다면,통계는 효율적인 통계 즉, 적은 양의 샘플을 통해서 추정하는 것이며 이후 검증이 필요하나, 머신러닝을 많은 데이터들을 분석하기에 추정이나 검증이 필요가 없어지면, 품질의 데이터가 많으면 많을수록 오타가 적게됩니다.
5. AI(Artificial Intelligence) 역사
인공지능의 역사는 intellegence를 무엇으로 정의 내리냐에 따라 결정을 나눌 수 있다.
|
1943
|
|
두뇌 논리회로 모델링
|
|
1956
|
|
다트머스 회의에서 AI 용어 탄생
|
|
1956 -1970
|
1차 인공지능 붐
|
수동적 대화 시스템(지능은 기호 처리)
|
1차 인공지능 세대 지능(Intelligence)은 기호 처리이다.예시) 아침 먹었어? 응, 아니 와 같은 챗봇, 인공지능스피커 같은 느낌)
하지만, "아침 먹었어?" 라는 말은 "오늘 아침 먹었어?" 라는 의미이지, '평생 아침을 먹은 적이 없었어?' 라는 질문이 아닐 것이다. 즉, 고려해할 범위의 문제로서 어려움을 맞이하게 된다.
|
1971 -1979
|
1차 빙하기
|
프레임(고려해야 할 범위)의 문제
|
|
1980 -1995
|
2차 인공지능 붐
|
전문가 시스템 활용(지능은 지식)
|
|
1996 -2000
|
2차 빙하기
|
지식 획득 병목의 문제
|
그러다가 1980-1995년대 지능은 지식이라는 아이디어가 등장하였다. Data를 정제하면, Information이 되며, 이를 정제하면 Knowledge가 되고 최후단계에서는 wisdom이 된다. 하지만, 모든 지식을 시스템에 넣는 것 자체가 어렵기에 2차 빙하기가 오게 되었다.
|
2010 - 2018
|
3차 인공지능 붐
|
빅데이터와 딥러닝(지능은 학습)
|
# Machine Learning / Artificial Intelligence에 대해서는 많이들 들어봤을 것이다. 머신러닝은 통계기반이며, AI는 애플리케이션처럼 이를 활용하는 단계이다.
그리고 현재 3차 인공지능 세대에서는 지능은 학습이다.라는 아이디어로 현재까지 진행되고 있다. 즉, 데이터를 통해서 특징을 기억하고 사용하는 과정을 통해서 학습(디지털 데이터 학습)을 하게 된 것이다.
다시 말해, 현재 시점은 우리가 가지고 있는 디지털 데이터를 통해서 학습을 시키고 있는 과정이다. 그렇기에 머신러닝, 딥러닝, 강화 학습과 같이 러닝(learning)을 붙이는 이유가 여기에 있다.(개인적으로 특강을 듣다가 이 부분에서 소름돋음)
6. 학습
그렇다면 대체 학습이란 무엇일까요?어떤 작업에 대해 특정 기준의 측정한 성능이 새로운 경험으로 인해 향상되었다면, 그 프로그램은 어떤 작업에 대해 특정 기준의 관점에서 새로운 경험으로부터 배웠다고 말할 수 있다.
그 과정은 아래의 그림처럼 표현할 수 있다.
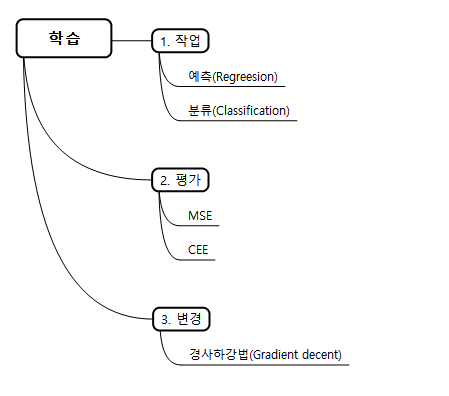
머신러닝의 학습과정
우선 크게 작업은 예측과 분류로 나눠지게 된다. 이를 평가하는 방식은 MSE(예측), CEE(분류)으로 나눠진다. (여기서 E는 Error를 의미하며, error가 낮으면 예측 또는 분류의 성능이 높아진다는 것을 의미)
※ 머신러닝에서는 이를 Loss/cost라고 한다.
학습을 시키는 이유는 오류를 작게 만들기 위함이다. 즉, 변화를 통해서 값의 오차를 줄여야한다. 그 방법 중 하나가 경사하강법(Gradient Decent)이다.
조금 쉬운 예를 들어보면 이해가 금방 될 것이다.만약 자신이 토익공부를 위해서 800점을 받았다고 하자.자신의 목표가 900점이라는 목표를 위해서 800점 받은 것처럼 공부를 하면 될까? 다른 결과를 위해서 다른 행동을 해야 하듯이 기존의 방법을 변경해야 한다.
7. Machine Learning
지금까지 머신러닝의 러닝에 대해서는 알아보았다. 그렇다면 이제부터는 MACHINE에 대해 알아보자. 머신은 모델, 알고리즘, 수학의 함수라고 생각할 수있다.즉, 머신러닝이란 함수를 학습시키는 작업인 것이다. 그중 가장 쉬운 것이 바로 선형 방정식(1차 방정식)이다.
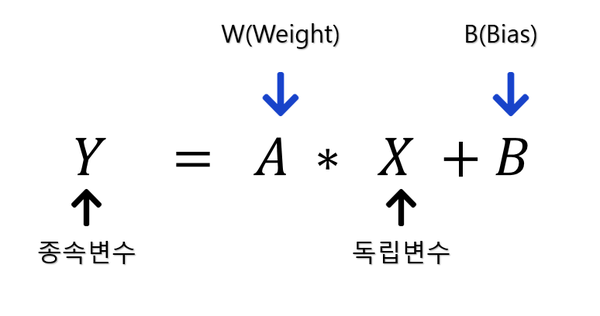
머신러닝에서는 A 대신 W(가중치, Weight), B(Bias)라고 사용한다. 통계학에서는 모수추정법이라고 하며, 머신러닝에서는 parameter(파라미터)라고 한다. 머신러닝은 데이터의 모양을 설명할 수 있는 모델, 함수를 찾고 싶은 게 목적이다.
- 통계: LSM 최소제곱법을 이용한 검증 단계가 존재
- 머신러닝: 검증 없이 MSE 값이 작으면 됨
마무리
우리가 궁극적으로 만들고 싶은 것은 지능이다. 그 지능을 통해 할 수 있는 작업은 예측과 분류이다. 그 작업의 잘 되었는지 안되었는지를 파악할 수 있는 기준은 에러를 통해서 알 수 있으며, 그 평가를 좋게 하기 위해서는 파라미터를 변경함으로써 오차가 제일 작아지는 에러를 찾아가야 하는 것이다.
Loss : (y -y 햇)**2
cost : mean(y-y 햇)**2 : 오차의 모양은 2차 함수 형태
MSE : mean square error
'Python > 2️⃣ 데이터 처리' 카테고리의 다른 글
| [머신러닝] 타이타닉 생존자 예측하기 (0) | 2023.02.06 |
|---|---|
| [머신러닝] 사이킷런으로 시작하는 머신러닝 (0) | 2023.02.06 |
| [알고리즘] 각도기 (0) | 2023.01.12 |
| [Kaggle]Binary classification : Tabular data (0) | 2022.08.15 |
| 차원 축소(Dimension Reduction) (0) | 2022.02.06 |