
주제: 웹크롤링으로 데이터다운 자동화하기 - 데이터 준비
작성: 2023-07-30
버전: python 3.9
발단
요즘은 "지구온난화", "기후변화"가 일상에서 실제로 체감되는 듯합니다. 기온상승과 더불어 문제는 것은 바로 해수온도입니다. 해수온도가 상승하면서 바다의 용존 산소량이 줄어들어, 바다가 머금을 수 있는 이산화탄소의 양이 줄어들게 됩니다. 이는 대기 중에 이산화탄소의 양이 증가하되며, 지구온난화 효과는 더 강화되는 악순환의 고리가 이어지게 되는 것이죠.
그래서 파이썬으로 직접 해수면의 온도를 직접 시각화하며, 연도별 변화를 확인하고 싶다는 생각이 들게 되었습니다.
관련 포스팅은 총 3개의 시리즈로 구성되며, 해당 포스팅은 첫 번째인 데이터 준비에 해당됩니다.
1. 데이터 준비 - SST(Surface Sea Temperature) 데이터 찾기 및 다운로드
2. 데이터 파악 및 시각화
3. 데이터 해석
데이터부터 찾자 !
해수면 온도변화를 확인하는 데 사용할 수 있는 데이터는 여러 과학 연구기관과 기상 관련 기관에서 제공하고 있습니다.
이러한 데이터는 공공목적으로 대부분 공개되어 있으며, 특정 지역 또는 전 세계 지역 등으로 공간적인 범위가 다양합니다.
대표적인 기관으로는 다음과 같습니다.
- 미국 해양대기청 (NOAA) ❣️
- 국가 기후데이터센터 (NCDC)
- 국제기후변화연구센터 (ICCG)
- 유엔 기후변화 지구관측소
다만, 저는 NOAA에서 제공하는 데이터로 진행하도록 하겠습니다.
- NOAA OI SST V2 High Resolution Dataset
https://psl.noaa.gov/data/gridded/data.noaa.oisst.v2.highres.html

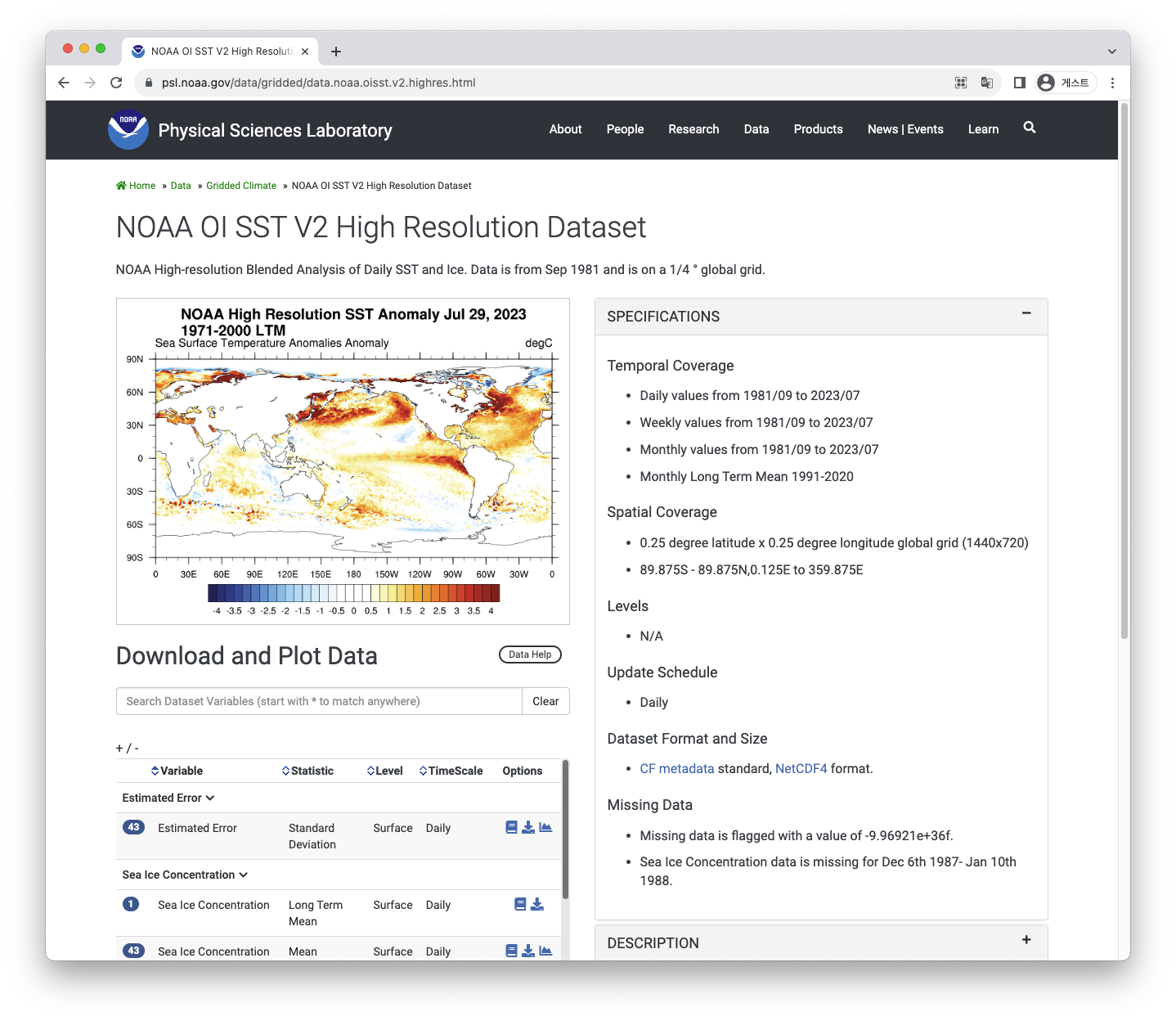
다운로드 버튼클릭하여 확인이 가능합니다.
SST day mean데이터의 경우, 1981년부터 2023년까지 데이터가 존재하는 걸 확인할 수 있습니다.
- 데이터 : 43개의 nc파일
- 데이터 기간: 1981년부터 2023년
- 데이터 총 용량 : 19,066M

전체코드
해당 데이터저장소에서 본인이 원하는 데이터들을 한번의 클릭으로 다운로드하는 시스템이 없다보니, 일일히 클릭해서 다운로드하는 방법밖에 없습니다. 하지만, 이러한 반복적인 누구보다 컴퓨터가 잘합니다. 다운로드를 자동화할 수 있는 코드는 다음과 같습니다.
import requests, os, time
from bs4 import BeautifulSoup
# 디렉토리 생성
save_directory = "sst_nc"
if not os.path.exists(save_directory):
os.makedirs(save_directory)
# 다운로드 사용자함수
def download_file(file_url, save_path,chunk_size=8192):
with requests.get(file_url, stream=True) as response:
response.raise_for_status()
with open(save_path, "wb") as file:
for chunk in response.iter_content(chunk_size = chunk_size):
file.write(chunk)
# 기본 URL
base_url = "https://psl.noaa.gov/thredds/fileServer/Datasets/noaa.oisst.v2.highres/"
# 시작 및 종료 연도 설정
start_year = 1981
end_year = 2023
for year in range(start_year, end_year + 1):
file_name = f"sst.day.mean.{year}.nc"
file_url = base_url + file_name
save_path = os.path.join(save_directory, file_name)
loop_start_time = time.time()
print("Downloading:", file_name)
download_file(file_url, save_path, chunk_size=65536)
loop_end_time = time.time()
execution_time = loop_end_time - loop_start_time
print(f"Time taken for {file_name} : {execution_time : .2f} sconds ")
print("Download completed!")특이사항 없이 작동됨을 확인했습니다.


코드상세 (1)
해당 코드에서 필요한 라이브러리를 import합니다. 해당 데이터를 저장할 디렉토리를 만들도록 하겠습니다.
- 디렉토리를 따로 생성하지않으셨다면, 원하는 디렉토리 명을 기입합니다.
- 이미 디렉토리를 생성하였다면, 생성위치를 기입하시면 됩니다.
import requests, os, time
from bs4 import BeautifulSoup
# 디렉토리 생성하기
save_directory = "./ 원하는 디렉토리명을 기입하세요"
if not os.path.exists(save_directory):
os.makedirs(save_directory)코드상세 (2)
다음은 URL 코드분석입니다. 각 연도별 클릭할때, URL의 변화를 분석합니다.
분석결과, 기본 URL 뒤에, 연도만 지속적으로 변경되는 것을 확인하였습니다.
그럼, 이제 코드를 본격적으로 작성해보도록 하겠습니다.
# 기본 URL
base_url = "https://psl.noaa.gov/thredds/fileServer/Datasets/noaa.oisst.v2.highres/"
# 시작 및 종료 연도 설정
start_year = 1981
end_year = 2023
# 반복문
for year in range(start_year, end_year + 1):
file_name = f"sst.day.mean.{year}.nc"
file_url = base_url + file_name
save_path = os.path.join(save_directory, file_name)
print("Downloading:", file_name)
download_file(file_url, save_path, chunk_size=65536)
print("Download completed!")
코드상세 (3)
막상 코드를 위의 코드처럼 for문 구동을 해보니, 각각의 파일 다운받는 소요되는 시간이 얼마나 되는지 궁금해집니다.
이런 경우에는, time을 이용해서 각 파일 다운받기 시작하는 시간과 다운 완료된 시간의 차이를 통해서 소요시간을 알아보도록 하겠습니다.
코드상세(2)에서 달라진 부분만 주석을 남겨놓았습니다.
for year in range(start_year, end_year + 1):
file_name = f"sst.day.mean.{year}.nc"
file_url = base_url + file_name
save_path = os.path.join(save_directory, file_name)
loop_start_time = time.time() # 다운로드 시작 전 시간측정
print("Downloading:", file_name)
download_file(file_url, save_path, chunk_size=65536)
loop_end_time = time.time() # 다운로드 완료 후 시간측정
execution_time = loop_end_time - loop_start_time # 다운로드 소요시간
print(f"Time taken for {file_name} : {execution_time : .2f} sconds ")
print("Download completed!")
코드구동에 오류가 있는 경우, 댓글로 문의 부탁드리겠습니다.
감사합니다.
Reference
- https://www.theguardian.com/science/2023/jul/27/scientists-july-world-hottest-month-record-climate-temperatures
- https://www.theguardian.com/science/2023/jul/27/scientists-july-world-hottest-month-record-climate-temperatures
- 북금곰 사진출처 : <a href="https://kr.freepik.com/free-vector/polar-global-warming-composition_26765766.htm#query=%EC%A7%80%EA%B5%AC%20%EC%98%A8%EB%82%9C%ED%99%94&position=4&from_view=keyword&track=ais">작가 macrovector</a> 출처 Freepik
‘Era of global boiling has arrived,’ says UN chief as July set to be hottest month on record
Head of World Meteorological Organization also warns ‘climate action is not a luxury but a must’ as temperatures soar
www.theguardian.com
'Python > 2️⃣ 데이터 처리' 카테고리의 다른 글
| GK2A LSM(Land/Sea Mask) 데이터 이해와 활용 방법 (1/2) (14) | 2024.01.14 |
|---|---|
| 파이썬으로 데이터 마스킹하기 - Numpy.ma (1) | 2024.01.10 |
| [머신러닝] 랜덤포레스트 예시 - Pima Indians Diabetes Database (0) | 2023.03.04 |
| [머신러닝] 결정트리 실습 - Pima Indians Diabetes Database (0) | 2023.03.03 |
| 간단한 통계 개념 정리 (0) | 2023.02.14 |